Revisiting the Unreasonable Effectiveness of Data
23 Jul 2017Paper: arxiv
Blog post: blog link
Key idea:
We believe that, although challenging, obtaining large scale task-specific data should be the focus of future study.
Some points:
- Better Representation Learning Helps.
-
Performance increases linearly with orders of magnitude of training data.
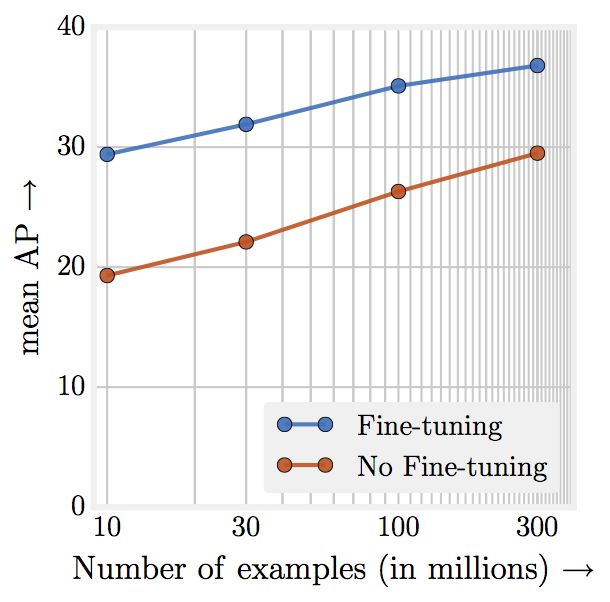
- Capacity is Crucial. (network capacity need to be large to learn more data)
- New state of the art results. (a single model (without any bells and whistles) can now achieve 37.4 AP as compared to 34.3 AP on the COCO detection benchmark.)